



Java in 2024, final touches before Kotlin 2.0, and a new ML-based static profiler for GraalVM – JVM Weekly vol. 82
We return to the standard edition today, one of the longest ever as it has grown significantly because many topics have accumulated. But I hope you like it :)


1. What the "2024 State of the Java Ecosystem" tells us.

Lots of reports lately. Only a fortnight ago I devoted an entire edition to Datadog's statistics on the level of security of Java applications, and in the meantime the 2024 State of the Java Ecosystem from New Relic has managed to appear. This is probably the first publication of its kind this year (are you embracing the fact that we're almost at the halfway point of it already 🥶?). So let's have a look at what's interesting to read from it - I've focused here on my insights, the report itself is quite a bit broader.

The report focuses heavily on the faster adoption of JDK 21 than JDK 17, but these single percentages are a statistical error from my perspective anyway. Much more interesting, I think, is that the increases in JDK 17 usage, however, seem to be mainly due to the cannibalisation of JDK 11. Assuming that New Relic itself is growing (13.48% year-over-year growth), it is reasonable to assume that in absolute numbers the amount of JDK 1.8 workloads is stable and most projects will stay on it.
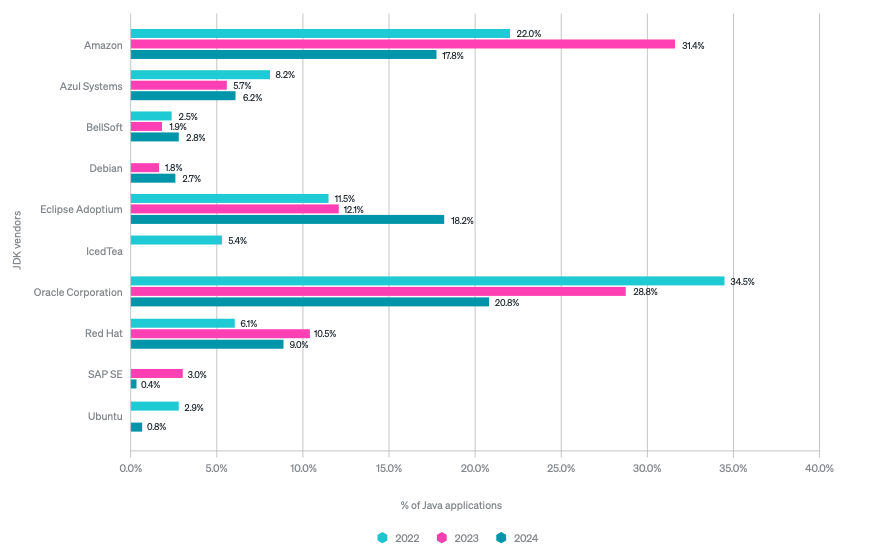
What I'm personally insanely happy about is how strongly Adoptium is breaking through into the mass consciousness. I myself notice that there is a slowly increasing awareness among the community and companies that Adoptium is not some alien entity, but simply a legitimate JDK variant worth using. However, I have to admit that I find it very difficult to understand such a dramatic drop in Corretto's popularity and it looks to me rather like some kind of error in reporting results, methodology - New Relic report is based on telemetry, so it's possible that Amazon internally started using some other JDK and this has affected services so much. New Relic - I'd love to hear if you have any thoughts on this not included in the report.
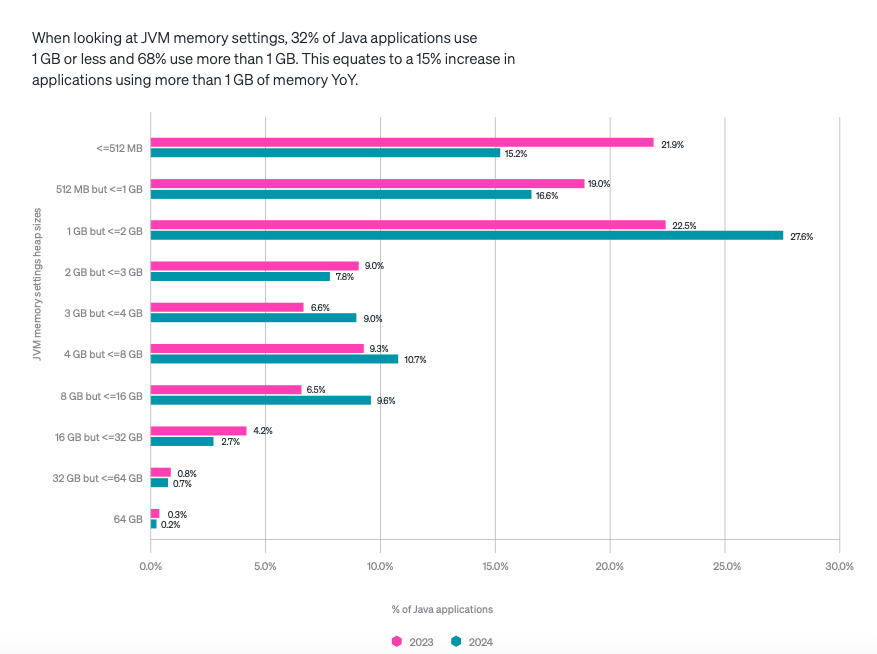
What I find very interesting is the observation that there is a significant disconnect between the adoption of G1 as the default Garbage Collector and the trend of reducing the CPU Core available to applications. These two are at odds with each other, as G1 was created for multi-core environments. What New Relic's report doesn't show is whether the increases in both of these trends really apply to the same applications, but I suspect that not everyone has read the 'fine print' after all.

And finally, I should definitely take an interest in the Bouncy Castle library. I have added it to my personal 'radar'.
2. Final touches before the release of Kotlin 2.0

Let's skip seamlessly over to Kotlin - because you can see that preparations for the big K2 release are underway and we've received some interesting announcements and publications. The first is the official migration guide, regularly updated with changes in the next RC versions of Kotlin 2.0, plus a good introduction to the new syntax options that were also recently introduced to Kotlin, so that they caught on to the guide for those looking to upgrade their codebase.
This, however, is not the only one of the new publications from JetBrains. Indeed, last weeks also saw the publication of K2 Compiler Performance Benchmarks and How to Measure Them on Your Projects, not only presenting the benchmarks, but also explaining the technical reasons for the changes in the performance characteristics of individual applications. A fundamental change in K2 (and mainly in its frontend) is the use of a single integrated containing data structure. With this change, the compiler not only manages one data structure instead of two, but also uses additional semantic information, which improves both the compilation process and code analysis in the IntelliJ IDEA environment. This innovation not only improves compilation efficiency, but also facilitates the implementation of new language features, especially in the context of Kotlin Multiplatform's drive to unify cross-platform support, which is one of K2's main goals.

According to the results presented, the performance of the Kotlin K2 compiler looks impressive, especially when compared to the previous version. The work on the new architecture of the compiler, which included rewriting it from scratch, resulted in significant improvements in compilation speed. These changes are particularly noticeable in the various compilation phases. Text from JetBrains states that in the Anki-Android project, for example, the compilation time 'from scratch' (clean build) has decreased from 57.7 seconds in version 1.9.23 to 29.7 seconds in version 2.0.0, a gain of 94%. Similar improvements were seen in the initialisation and analysis phases, where speed increases of 488% and 376% were recorded, respectively. These improvements are due to the implementation of a new type inference algorithm and new IR backends for the JVM and JS, which, together with the new frontend, significantly speeds up compilation processes. That said, the authors also caution about monitoring and adjusting compilation processes using tools such as Kotlin build reports to help understand and optimise compile times.
And very rightly so, as the above is data from JetBrains themselves, being the judge in their own case- which is why it's nice that we're starting to see publications from outsiders. In his detailed review of the upcoming version of Kotlin K2, Zac Sweers of Slack shares his insights into the improvements to K2, but also the challenges involved. He takes an icing-free and sober look at them, highlighting that the sharper error detection in K2, particularly around nullability support, on the one hand promises cleaner coding practices, but on the other may require developers to respond to new warnings or errors, which can initially be problematic. Sweers also points to significant changes in the handling of compiler suppression mechanisms and the introduction of more advanced type casting capabilities. In addition, he warns of potential integration issues with Gradle, especially for complex or multi-platform projects, and highlights the need to adapt compiler plug-ins due to API updates between Kotlin versions.
As for the performance just described, Sweers shares a mix of results based on his tests, which contrast with JetBrains' promises of significant out-of-the-box improvements. While some projects may see modest improvements, others experience slowdowns, suggesting a variable impact in different environments. For example, experiments in Slack showed a reduction in performance of around 17%, at least when still using KSP 1. Another project, CatchUp, saw significant improvements, but another project, Circuit, again experienced similar slowdowns. This highlights the need for people to do their own performance testing to fully understand how changes to K2 will affect their projects - every build is slightly different, and today's project compilation process is complex enough that not every application will enjoy 'free' performance gains. In many cases, we will need to take the way we build applications under a magnifying glass.
And that's not the end of the news around Kotlin 2.0, as Google's Ben Trengrove and Nick Butcher have announced that as of this release, Jetpack Compose will now be included in the Kotlin repository, ensuring that Compose is kept up-to-date with new versions of the language. This integration eliminates the delays that developers previously faced when updating Kotlin in Compose applications. In addition, a new Compose Compiler Gradle plugin has been introduced that simplifies project configuration with a special DSL. Google's Compose team will continue to develop the compiler in collaboration with JetBrains.

And speaking of Kotlin, I'll remind once again I'm going to KotlinConf this year! As such, expect a detailed report, I'll be doing my best to summarise the whole thing, writing reports as I go along 😀
3. GraalSP - new static profiler for GraalVM

And now what tigers like best.... The new whitepaper. And not just any whitepaper, from the GraalVM team. I've only just finished wading through their original publications, and here's a new one on further profiling improvements.... further blended with Machine Learning.
But before we skip ahead, it is first time to define two terms - static profiling and dynamic profiling, two different approaches to code analysis and optimisation in the context of Ahead of Time (AOT) compilation. Static profiling, based on heuristics and structural analysis of the source code before execution, does not take into account input data or execution conditions. While effective for pre-optimisation, such as inlining or dead code elimination, it may not take into account all real-world usage scenarios, which can lead to sub-optimal performance under unforeseen conditions.
Dynamic profiling, on the other hand, takes place during the actual execution of the programme and collects data about its behaviour using counters at key points. This method allows very fine-tuning of the optimisation to the actual running conditions of the application, which is beneficial in changing environments. However, dynamic profiling requires additional performance load at execution time due to the need for data collection, which can negatively affect the application's response time. Additionally, preparing appropriate test scenarios is a feat in itself, as anyone who has ever try to properly warm up their application before launching it in production knows.

A paper GraalSP: Polyglot, efficient, and robust machine learning-based static profiler, by Milan Čugurović, Milena Vujošević Janičić , Vojin Jovanović and Thomas Würthinger, was published last week. GraalSP is a new solution for GraalVM, which tackles the challenges of static profiling by using machine learning to generate profiles more efficiently. Thanks to the use of a high-level graph intermediate representation (a Graal trademark), GraalSP is both portable and polyglot, allowing it to be used in various languages that compile to Java bytecode, such as Java, Scala or Kotlin (so moderately polyglotted compared to even Truffle, but still probably takes a ton of work away from developers). It uses the XGBoost model, which is more efficient than the deep neural networks used in other ML-based profilers, minimising compilation time and complexity.
Additionally, GraalSP enriches its functionality with branch probability prediction heuristics that provide higher performance for compiled programmes, even in the case of inaccurate profile predictions. This increases the robustness of the optimisation, minimising potential negative impacts on the performance of the final product. This approach makes GraalSP particularly valuable in dynamically changing execution environments. Integration of GraalSP with the Graal compiler reportedly demonstrates the practical benefits of this solution, achieving execution time speed-ups of 7.46% on average compared to a standard compiler configuration.
Generally, I recommend the whole paper - it is available to anyone interested. I expect we'll get some news about the project being pulled into the main branch soon, maybe already with GraalVM for JDK 23?
UPDATE: GraalSP has been part of GraalVM since June 2023; it's just that the relevant paper is only now being published - Thanks for the clarification, @Milena Vujosevic Janicic 🙇.

And while we're on the GraalVM announcements, it's time to move on to Release Radar.
4. Release Radar

Graal Development Kit for Micronaut 4.3.7
Remember the Graal Cloud Native project? It was a set of modules created at Oracle designed specifically for Micronaut, facilitating the development of cloud applications by offering a carefully selected set of modules of the Micronaut framework. These modules were designed for Ahead-of-Time compilation using the GraalVM Native Image and aimed to provide developers with platform-independent APIs and libraries covering major cloud services such as Oracle Cloud Infrastructure (OCI), Amazon Web Services (AWS) and Google Cloud Platform (GCP), with planned future support for Microsoft Azure.
The project has evolved, and with the introduction of the new version of Graal Cloud Native, it has been rebranded as the Graal Development Kit for Micronaut. This renaming was influenced by user feedback and a desire to more closely align with the Micronaut branding, clearly reflecting the project's purpose and vision. I appreciate the simplicity and the direct approach - explaining what Graal Cloud Native was proved to be quite challenging, but now, the project's focus is immediately obvious (funnily, we'll delve into Oracle's naming conventions once again today).
In addition to renaming the Graal Development Kit for Micronaut 4.3.7 updates base Micronaut version to 4.3.7 (did I mention I like things to be simple and clear!), ensuring compatibility between its modules and dependencies, helping to minimise the risk of incompatibility with the library ecosystem. In addition, the Graal Development Kit now supports both Java 21 and Java 17, and has increased compatibility with options for Ahead-of-Time compilation derived from Oracle GraalVM. Additionally, the release includes new guides for creating, deploying and running serverless features on major cloud platforms, as well as updates to developer tools and extensions for environments such as IntelliJ Idea and Visual Studio Code.
Quarkus 3.10
Quarkus 3.10 is primarily about improvements in data layer support, including a new POJO Mapper module derived from Hibernate Search. This feature allows direct indexing of arbitrary POJO (Plain Old Java Objects) objects, making it easier to handle structured data from a variety of sources, such as MongoDB files and entities. Additionally, Quarkus 3.10 updates its integration with Flyway to version 10, which resolves previous compatibility issues with native executions and offers improved database migration tools.
This release also includes changes to configuration management by reorganising the quarkus.package.* configuration parameters, which on the one hand will make it easier to extend and maintain their growing subset in the future, but on the other hand may in some cases require manual migration. Quarkus 3.10.0 also brings updates to Quarkus CXF, a tool that enables the creation and consumption of SOAP web services.
The final set of fixes relates to Securit, which received several enhancements in Quarkus 3.10. These include the ability to select authentication mechanisms for REST endpoints using annotations, optional encryption of OpenIDConnect session cookies, and support for custom validation of JWT OIDC claims using Jose4j dependencies and the new TokenCertificateValidator.
Hibernate 6.5
And since there's so much database-related news in Quarkus, it's also worth looking at Hibernate 6.5. This update introduces improvements to the handling of Java Time objects in line with the JDBC 4.2 specification. Previously, Hibernate managed Java Time objects using intermediate forms like java.sql.Date, java.sql.Time, or java.sql.Timestamp. However, the new update allows for objects such as OffsetDateTime, OffsetTime, and ZonedDateTime, which contain explicit time zone information, to be passed directly. This significant change moves away from older methods where time zone information was lost due to the limitations of java.sql variants.

The update also includes changes to the query cache configuration. This is because the move from a 'shallow' to a 'full' representation of entities and collections in version 6.0, which aimed to reduce the number of database calls by storing full data for fetch join results in the query cache, resulted in increased memory usage and potentially more Garbage Collector activity. Version 6.5 therefore allows users to configure the cache - this can be done globally or on a per entity/collection basis, with better defaults automatically choosing between shallow and full cache layout depending on the storage capabilities of the entity/collection in question, providing a balance between performance and memory efficiency.
In addition, Hibernate 6.5 now supports the use of Java records as @IdClass, which improves annotation capabilities and simplifies entity identification.
record PK(Integer key1, Integer key2) {}
@Entity
@IdClass(PK.class)
class AnEntity {
@Id Integer key1;
@Id Integer key2;
...
}
This version also includes improvements for StatelessSession, such as support for filters and SQL logging, and for Session and StatelessSession automatic filter enablement has also been introduced. UPDATE and DELETE queries, meanwhile, can now use Hibernate joins. Another very useful new feature is the ability to manually assign identifiers even when they are annotated with @Generator. In addition, there is also key-based pagination and an ON CONFLICT clause for insert queries, offer more control to the user.
The release is also accompanied by Hibernate Reactive 2.3, supporting the functivities of Hibernate ORM 6.5.
Devoxx Genie
Devoxx season is underway, and we'll probably be breaking through the conference videos in a while, but in the meantime it's worth mentioning a project by Stephan Janssen, creator of the Devoxx(4kids) initiative. For he has created Devoxx Genie, which is a plugin for IntelliJ IDEA designed to work with both local and public LLMai (such as OpenAI, Anthropic and the like), using popular tools (such as Ollama, LM Studio or GPT4All).
Like other tools of this type, offering features such as code clarification, code review and automatic generation of unit tests or chat from within the IDE. Standard, but what's especially cool is that in this age of closed solutions Devoxx Genie is a fully open-source project, written in Java, so everyone can see how it was built. I recommend it if you like to read the code sometimes, it encouraged me to reactivate my old Github All-Star series. It's the umpteenth time I've threatened to do so, maybe one day I'll finally do something with it.
But that's not the end of Code Assistants, because I've left myself cherry for the very top of today's cake...
Oracle Code Assist
And in the end we will break the rules once again anyway (it was supposed to be a regular edition, and instead of three sections there are four...). We started Radar with Oracle and we will end it with Oracle, specifically with the announcement of a release.... but not just any release.
Oracle has indeed announced that it is working on its own Code Assist. Oracle Code Assist (perhaps not very creatively, but I prefer it to the 'creative' naming of AWS services) is supposed to differentiate itself from other similar solutions, such as GitHub Copilot or Amazon CodeWhisperer (though we'll come back to that), by specialising in Java and SQL and integrating deeply with Oracle Cloud Infrastructure (OCI). The tool is reportedly designed to optimally support the specific needs of developers working in the Oracle ecosystem.

While GitHub Copilot supports a broad array of programming languages, Oracle Code Assist zeroes in on offering highly tailored code suggestions. It focuses on popular Java libraries, SQL, and programming practices unique to Oracle solutions. This specialization aims to provide more precise and efficient support for developers working on enterprise applications. It's quite logical when you think about it. Presumably, Copilot hasn't gleaned much about JDK 1.7, EJB 1.0, Struts, or Enterprise Service Bus implementations from GitHub. Hence, this fine-tuning could be very appealing to numerous enterprises.

Additionally, Oracle Code Assist will introduce Retrieval Augmented Generation (RAG) functionality, which will enable the secure merging of an organisation's source code and other data sources, providing code suggestions more tailored to an organisation's specific practices (although we all realise that this acumen will not always be an advantage, right?). Having said that, this type of functionality is rare among other coding assistants, giving Oracle an advantage in the context of corporate applications and regulated sectors where such customisation to specific needs is particularly valuable.
Just to clarify, GraalSP is officially deployed since June 2023 :-)
1. According to Google Translate, the first paragraph under the Hibernate section is:
"And since Quarkus has so many new features regarding databases, it is also worth taking a look at Hibernate 6.5, which, among other things, introduces improvements in the handling of Java Time objects in accordance with the JDBC 4.2 specification. Previously, Hibernate managed Java Time objects using intermediate forms of java.sql.Date, java.sql.Time, or java.sql.Timestamp, and the new update allows you to directly pass objects such as OffsetDateTime, OffsetTime, and ZonedDateTime, which contain clearly defined zone information time. This change replaces legacy methods where timezone information was not preserved due to limitations of java.sql variants."
Now you know.
2. Those adoption stats for the JDK versions are consistent with my (admittedly anecdotal) experience. JDK 17 is gaining at the expense of JDK 11.
3. Bouncy Castle is probably the most useful library with the silliest name ever. I respect that.
4. I'm glad you can use records as composite keys. Now if you could only use them as entities...
Great job as always :)