



Microprofile AI, Jakarta EE 12 and Jakarta Data: What’s New in Enterprise Java? - JVM Weekly vol. 106
Time to grow-up and "go enterprise".


1. Jakarta EE 12, Jakarta Data, and Microprofile AI – What’s New in Enterprise Java?

With Jakarta EE 12 work on the horizon, active discussions are shaping its direction, prompting me to explore the progress being made. The reason? Jakarta platform is indeed moving in an interesting direction, with a clear shift away from EJB, which was the backbone of the old platform for years.
EJB, or Enterprise JavaBeans (and the name alone might already ring ominously in your minds), is a technology developed by Sun Microsystems in the '90s to simplify building scalable, multi-layer applications for corporate environments. EJB provided essential mechanisms such as transaction management, remote method invocation, security, synchronization, and event handling in the Java EE application environment. Despite its popularity, EJB quickly gained a reputation as a "heavy" and complex technology, requiring extensive interfaces and configuration. Additionally, creating and deploying components was more complicated than in competing frameworks, gradually earning EJB an outdated image.

As Java EE evolved, Contexts and Dependency Injection (CDI) was introduced in response to these challenges, officially appearing in Java EE 6 in 2009. CDI allows for using lighter, more flexible mechanisms for dependency injection, component lifecycle management, and defining operational contexts. CDI brought programming capabilities similar to those offered by the Spring framework, including the ability to define "lightweight" components without complex configurations. The evolution of CDI was significant, allowing developers to achieve many features previously available only in EJB, like lifecycle management, transactions, and resource sharing, but in a more modular and flexible way. Over time, CDI became the preferred technology in Jakarta EE-based applications, leading to the current discussion about fully replacing EJB in future platform versions.
In the document about Jakarta 12 plans, published by Reza Rahman on the public mailing list of the Jakarta EE working group, the future of EJB and its potential replacement with CDI as a more flexible tool for application component handling comes up. Many participants in the discussion highlight EJB's outdated nature, which, although rich in features like transaction management, security, and remote call handling, has been labeled a "heavy" architecture over the years, creating not only an image problem but a technical one. This part of the community argues that EJB is not only difficult for new users but also drives them towards alternative technologies like Spring, which offers lighter solutions. There is a call for a strategy to move away from EJB and migrate to CDI, which would enhance Jakarta EE’s competitiveness—even this week, Bauke Scholtz published an article titled How to Migrate from EJB to CDI?, describing such a process.
On the other hand, a group of developers defends EJB, arguing that it still provides useful mechanisms like automatic transaction management and safe concurrency handling that are not fully available in CDI. They emphasize that migrating to CDI requires additional effort and that for some projects, it may increase code complexity. In response, there are proposals to include migration guides in Jakarta EE 12 and to develop new CDI stereotypes (special annotations that allow grouping several frequently used annotations into one) to enable using the same functionalities as EJB in a more modern way. Additionally, documentation updates are considered to better reflect the transition from EJB to CDI and to limit references to the former.
In general, I recommend following the mailing lists. It’s nice to see smarter people than me discussing things in a meaningful way.
And that’s not the only interesting discussion this week. The community of a Jakarta EE-related project, MicroProfile, is intensively working on introducing an artificial intelligence API (understood as LLMs) into its ecosystem. The MicroProfile AI initiative, launched in March 2024, has quickly gained momentum, and the group is currently facing a strategic decision regarding its technical foundation - they are considering directly adapting the API from the LangChain4J project by Dmytro Liubarskyi or creating their own dedicated MP AI interfaces. While popular, LangChain4J has some limitations, such as requiring JDK8 and dependencies on libraries like Lombok. An important aspect is also integration with existing MicroProfile technologies, especially with MP Telemetry.
A significant milestone in the project’s development was the creation of the SmallRye LLM reference implementation. Special attention was given to implementing the RAG (Retrieval Augmented Generation) pattern and integrating it with vector databases. The team is also working on CDI extensions that enable AI integration in various runtime environments, including WildFly, Quarkus, and Open Liberty. The initiative, inspired in part by the success of Spring AI, aims to create a comprehensive AI programming model within MicroProfile, along with an API for communication with language models (LLM) and integration with popular OpenAI libraries.
Experts from leading tech companies are involved in the project - Emily Jiang from IBM, Clement Escoffier from Red Hat, specialists from Oracle, as well as independent contributors. The group is currently focused on the practical aspects of implementation, laying the groundwork for future standardization within the MicroProfile specification.

Speaking of the future, we’ve recently seen the stable release of Jakarta Data, which has reached version 1.0. The primary goal of this project is to simplify interactions between an application’s domain logic and the data storage layer. A key element of Jakarta Data is the concept of a repository, defined through an interface annotated with @Repository. It acts as a mediator, handling different types of databases—both relational, NoSQL, and other data sources and in practice, works in the similar way to well-known Spring Data.
In the interface, you declare methods for fetching and modifying data for specific entity types. Notably, a single repository can handle different entity types, offering developers flexibility in designing structures that fit their business domains.
Here’s an example of what a repository interface might look like:
@Repository
interface Publishing {
@Find
Book book(String isbn);
@Find
Author author(String ssn);
@Insert
void publish(Book book);
@Insert
void create(Author author);
}Jakarta Data uses annotation system (like @Insert, @Find) to define persistence behaviors for specific methods and supports various providers that understand Java-specific annotations and know how to interact with different types of databases. For example, WildFly Preview introduces Jakarta Data support through the Hibernate Data Repositories implementation, which uses Hibernate ORM for interactions with relational databases. This implementation supports the jakarta.persistence.Entity annotation as a mechanism for developers to define entities. WildFly provides Jakarta Data in its Preview version, allowing developers to test and utilize this technology, with plans to include it in the standard WildFly version in upcoming releases.
There is a nice write-up about this topic from Brian Stansberry from Wildfly and, of course, there’s a must-see Devoxx presentation covering the entire project in detail by Gavin King.
Additionally, it’s worth mentioning the new WildFly 34 release, featuring Jakarta Data 1.0 support, a focus on MicroProfile REST Client 4.0, and MicroProfile Telemetry 2.0. It also updates integrations with Hibernate ORM and Hibernate Search. Moreover, it was announced that starting with WildFly 35, the server will require Java SE 17 as the minimum Java version, ending support for SE 11. This change is driven by the end of support for SE 11 in dependent libraries and aims to align with newer Java standards for improved functionality and compatibility. Users are advised to transition to SE 17 or later, with SE 21 recommended for stability.
WildFly isn’t the only application server, though. Its competitor, GlassFish, recently shared its roadmap for upcoming releases, summarizing recent updates and focusing heavily on Piranha Cloud—a modern, lightweight runtime environment for Jakarta EE that emerged as an alternative to traditional app servers like GlassFish and Tomcat. Piranha Cloud, based on GlassFish components, stands out for its modularity, allowing for a personalized environment containing only the necessary components. This enables both simple web app deployment and advanced control over the runtime environment.
Interestingly, this isn’t the first P-starting, cloud-named project in the ecosystem.
Nobody:
Still Nobody:
Payara: Let's create Cloud Serverless for Jakarta EE!
Last year, Payara Services Ltd decided to create Payara Cloud — a Platform-as-a-Service for Jakarta EE applications. It works by taking your Jakarta Web Profile-compatible .war file, uploading it to the cloud, and... voilà! Initially, my reaction was, "What won’t people think of?" and I almost moved on… but then it clicked, and from a practical standpoint, I can see how it makes sense and aligns well with Jakarta EE’s history.
Let’s be real - Java EE standards were originally developed to separate the language from specific implementations provided by various vendors. This approach perfectly fits the situation where infrastructure providers can deliver dedicated Jakarta-compatible APIs. Yes, we’re packaging everything into Docker these days, but really, these are just additional layers over a clean, scalable Serverless platform, as Payara promises.
If we consider application servers as runtime environments for applications (which they essentially are), the idea of "deploy a JAR/WAR and forget about it in a cloud-native way" sounds very tempting. It’s like history repeating itself, in a way.

2. What Does Java UI Development Look Like in 2024?

I’ll admit, the trend of so many UI tools emerging around Java has surprised me. I noticed individual “events,” but only recently did I realize it had become a big thing. So, I decided to make a quick rundown of the topic and highlight some random things that have especially caught my eye.
This article is directly inspired by the Kotlin Multiplatform Roadmap published last week by Egor Tolstoy, outlining JetBrains plans and priorities for 2025. It details ongoing development for Compose Multiplatform, developer tool improvements, and plans to port Kotlin to Swift. A key area will be Compose Multiplatform—a multi-platform framework based on Jetpack Compose that allows developers to create shared user interfaces for Android, iOS, Desktop, and Web applications. The roadmap emphasizes stabilizing the Compose Multiplatform experience on iOS, general framework stability, and enhancing Compose Multiplatform previews. Plans also include expanding Web platform support with drag-and-drop functionality, text input improvements, and interoperability with HTML content, as well as tooling enhancements.
Recently, Compose Multiplatform 1.7.0 was released, introducing iOS performance improvements, type-safe navigation, Material3 adaptive support, drag-and-drop on desktop, and better touch interaction on iOS. A lot is happening in the Compose project, and it’s clear there’s a lot of momentum.
But that’s not all. Vaadin has entered the scene with an AI assistant this year—finally, backend developers who panic at the sight of a CSS div can breathe easier. Vaadin Copilot combines WYSIWYG (what you code is immediately visible on screen) with AI for automatic fixes.
So, even if flexbox-es makes your hands drop in frustration (or you’re hearing the term for the first time), Vaadin Copilot knows what to do. I tried it at their Devoxx booth, and, to my surprise, it didn’t crash and handled things quite well! Although I discovered my creativity is… limited. I panicked and started positioning divs and adding alerts, so the bar was set pretty low.

PS: Have you seen Cursor IDE? The demos are impressive, and the creators are truly passionate. I know frontend devs who, despite denying the potential for AI to replace developers, got a little nervous after watching their demos.
Why UI in Java seems gaining popularity? The usual reason - money. Just look at WebForJ’s value proposition.
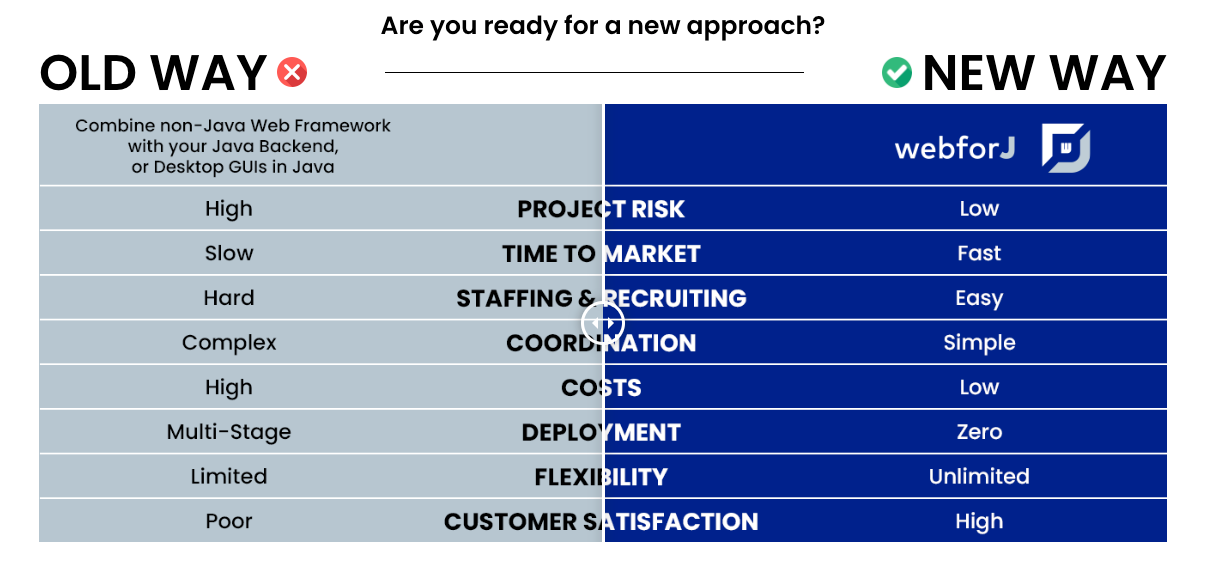
WebForJ is another tool that allows assembling UI from components, aiming to let Java developers take over the entire frontend without the need for frontend acquaintances, an additional team, or technical jargon. Want an application? You get one team and one tool that handles the entire interface—no need to learn new languages, or frameworks, or hire extra specialists. In short? One less team role, and more zeros in the bank.
Faster implementation time? Sure thing! No ping-ponging between departments means shorter project timelines. Fewer resources, fewer hours, lower costs. A value proposition fitting for 2024, and I think this full-stack team promise is the secret. In a world where TypeScript is wildly popular (PS: I enjoy the language, it was cool to explore their type system), letting you code both front and back end, a similar, but more backend-centric strategy is tempting.
But on the other hand, those cost savings can vary too—it reminds me of the honesty from the JetBrains team at the last KotlinConf, where someone on stage remarked that Compose or Flutter might not gain as much popularity simply because React Developers are just cheaper.
All right, component frameworks are a well-known concept, so here’s something more intriguing. Another "find" from recent conference visits is JxBrowser by TeamDev, whom I met at EclipseCon. It’s a Java library that allows integrating a Chromium-based browser directly into Java applications. Users can interact with dynamic pages, using Java APIs for communication between the application and browser, enabling two-way data exchange between the app and the web page content. For mobile platform developers, this might sound similar to the WebView concept.
What’s the point? Beyond standard use cases like reporting systems or BI tools, JxBrowser caught my eye for its more creative applications. For example, Google used JxBrowser in its Flutter plugin to embed Flutter DevTools directly into the IDE, eliminating the need to switch between browser windows and the development environment. This lets developers conveniently debug and monitor apps using browser functionalities rendered within the IDE interface. Such a solution not only enhances the development process for users but also reduces support costs for the plugin’s creators, as it allows the same DevTools version to be supported across different platforms.
Honestly, just when I thought the topic was buried and we’d moved past the days of GWT or JSF, the community seems to be giving it another go. I’ll be keeping an eye on whether this experiment turns out successful.
And since we’re on the topic of Java desktop, how could we skip JavaFX, especially with a new and interesting application in this technology? JTaccuino is a notebook developed for Java programmers, allowing users to interactively experiment with code. For those unfamiliar, notebooks are interactive applications that enable users to combine code with text, visualizations, and data, which is particularly useful in education, data exploration (with roots in Python environments), or algorithm testing. In JTaccuino, Java code is executed by JShell—Java's REPL—allowing dynamic code testing, quick prototyping, and effective learning. While Java might not be the ideal language for such applications, JTaccuino still offers a truly interesting solution.
Here’s a talk from Devoxx with all the details.
Finally, speaking of the JavaFX and AI mix, the DeepNets project, which is a reference implementation of JSR 381, recently boasted new tooling enhancements.
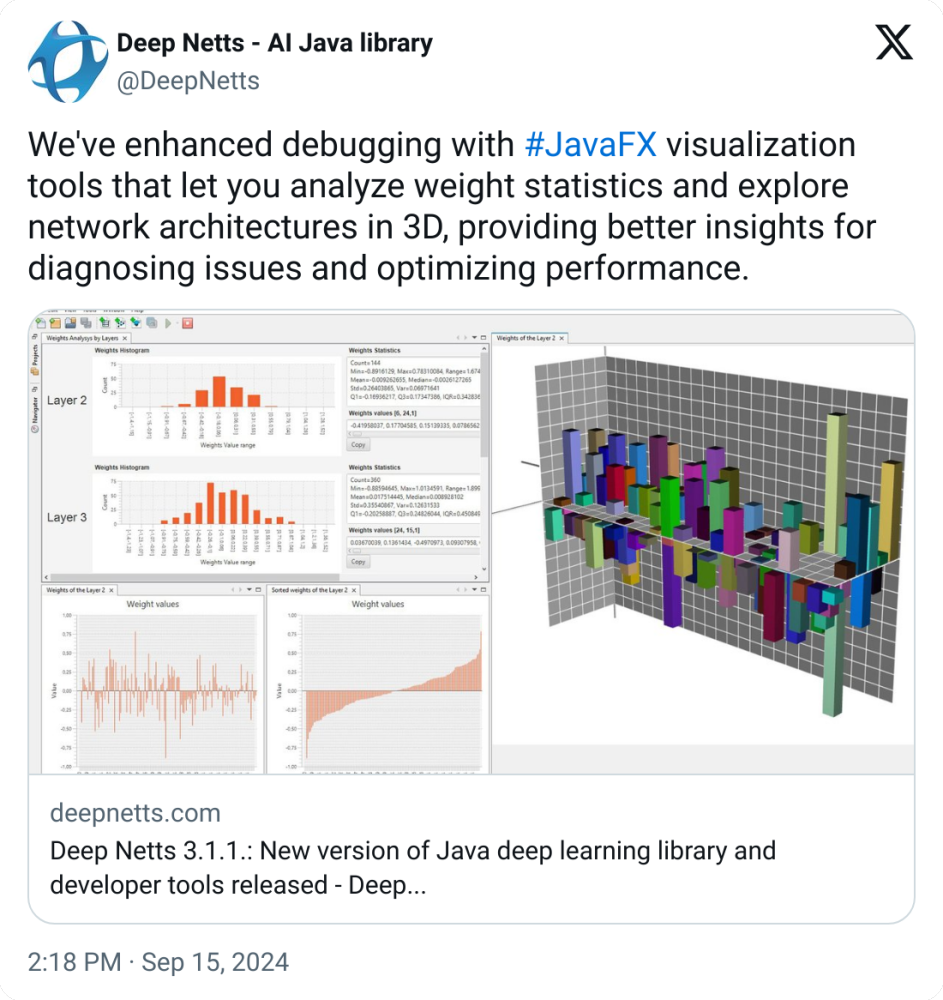
They’ve added JavaFX-based visualization tools for analyzing weight statistics and exploring network architectures in 3D. This makes debugging more intuitive, allowing users to better understand model functioning, enhancing diagnostic capabilities, and optimizing performance.
As you can see, although it remains a somewhat niche topic, a surprising amount is happening within it. I’m curious whether this is part of a long-term trend or just my recent bias kicking in, as I don’t yet see a strong trend across projects in this area.
3. TornadoVM brings LLama Support

Now, buckle up because it’s time for TornadoVM. We’re going deep.
For a refresher: TornadoVM is a specialized virtual machine that extends Java’s functionality by adding support for parallel processing across various compute units, such as GPUs and FPGAs. This allows developers to optimize applications with automatic acceleration of Java code processing without rewriting it in other languages or manually calling libraries written in C.
TornadoVM acts as a layer on top of the JVM, enabling dynamic switching between hardware architectures, which supports projects requiring high performance, like machine learning algorithms or large-scale data processing. You can learn more about TornadoVM architecture from Juan Fumero article The TornadoVM Programming Model Explained. For a long time, however, the platform had limitations preventing it from efficiently running models like LLama. Luckily, those days are over.
The initial port of Llama2 for TornadoVM was implemented by Michalis Papadimitriou earlier this year, and is available under llama2.tornadovm.java. This repository offers an enhanced version of the Llama2.java implementation, accelerated with GPU support through the Vector API and TornadoVM. The project requires JDK 21+ due to its use of Project Panama for native memory allocation, and TornadoVM, with installation instructions available for setup.
Additionally, in October, the TornadoVM team successfully ran a Llama2 model on TornadoVM using Level Zero JNI. Level Zero JNI is a library that bridges Java with Intel’s low-level Level Zero API, providing direct SPIR-V (a binary intermediate format that allows efficient code execution on various platforms, especially in GPU and Vulkan environments) support on Intel-integrated GPUs and Intel ARC within the TornadoVM Runtime. Although it includes only part of the full Level Zero API, it contains everything needed to run code effectively on Intel’s graphic hardware, bringing Java closer to "baremetal" programming in GPU and FPGA applications.
A project fork, extended with GPU support and developed by Michalis Papadimitriou, demonstrates how Level Zero JNI enables manual kernel control (small subroutines executed on GPUs) on Intel cards, achieving a higher number of tokens per second (tok/s) compared to TornadoVM’s automatic acceleration. Manual Level Zero JNI calls were essential, as they allow managing shared memory, significantly speeding up computations - though TornadoVM currently doesn’t support shared memory, as their next step is to use Panama segments as shared memory GPU buffers.
Not only is the Tornado team experimenting with running models on their VM, but Jürgen Schuck, author of otabuzzman/llm.java, recently described the process of migrating the llm.c project and its capabilities to run the GPT-2 model on TornadoVM. The first step was to convert C code into Java, requiring the transformation of pointers into array indexes…
Disclaimer: In C, pointers are used for direct memory access, but since Java has no pointers, arrays and their indices serve as proxies to specific data structure elements.

…and using Java Streams instead of OpenMP (a C library for straightforward parallel task execution) for parallelizing loops. Then TornadoVM was used to create a Task Graph—a structure enabling the sequential execution of model layers on accelerators like GPUs…which those who read the suggested article on TornadoVM architecture surely know. I really don’t share links without a reason.
Migrating to TornadoVM allowed leveraging the virtual machine’s ability to automatically accelerate sequential Java code, eliminating the need for manual memory management or GPU kernel calls. However, the process wasn’t without its challenges. During migration, technical issues arose: parallel loops required adjustments to enable proper TornadoVM kernel generation, and some model layers, such as matrix multiplication (matmul), needed code tweaks to avoid execution errors.
Despite these challenges, migrating to TornadoVM showed promising results, increasing model performance by around 35% compared to traditional C implementation. Once again, this proves TornadoVM can be a valuable tool for the entire ecosystem—and I’m rooting for them.
Coming back down to Earth, Nick Zhu from Microsoft recently announced a technical preview of its new GitHub Copilot assistant for Java upgrades. Unlike traditional tools or even competitive solutions, both traditional (like Spring Migrator or OpenRewrite) and AI-based (like Amazon CodeWhisperer For Java Developers or Oracle), GitHub’s assistant takes an agent-based AI approach. Instead of just suggesting changes, it actively plans, executes, and fixes issues during the upgrade process, maintaining a high level of autonomy while keeping its actions transparent.
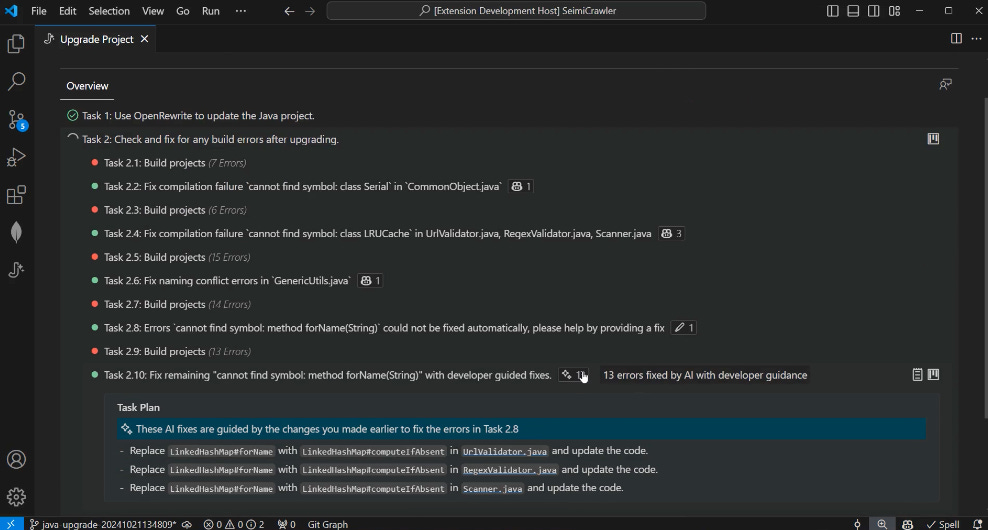
What particularly sets this solution apart is its ability to learn from developers’ manual corrections and its advanced autonomous debugging system. While other tools often stop when encountering errors, Copilot’s assistant tries to solve problems independently through a dynamic build-and-fix loop, only asking for human assistance as a last resort. With a transparent dashboard showing each step of the process and the option to pause or resume updates, Microsoft seems to be offering the most advanced tool of its kind on the market, though its actual effectiveness will only be measurable after broader testing... which I plan to try before AI takes over my job entirely.
Lastly, let’s look at the latest Spring AI examples published by Marcus Hellberg from Vaadin. The repository includes practical examples of using Spring AI in various scenarios. Key functionalities cover document processing (analysis and summarization), text sentiment analysis, content creation support, and image data extraction. I’m particularly interested in the samples related to advanced RAG (Retrieval Augmented Generation) techniques, which show how to combine information retrieval from multiple sources, improve result accuracy through re-ranking, and rephrase questions for better results.

Meme stolen from Konrad Bujak - couldn't resist, man.
And to wrap up, staying slightly on the topic of all things GPT:
I’m a simple guy - see Cthulhu, click the video. So, imagine my surprise when, after clicking on Ken Kousen latest video, I found it was based on an old joke of mine from Lambda Days 2016 in Kraków and those days when I seriously planned to become a practicing Clojure dev. I was in shock for quite a while.
PS: Highly recommend
- a great newsletter.PS2: Inspirations work both ways because Ken’s earlier videos gave me the idea to play around with Flux, which is why today's images have a different feel—same prompt, but a decidedly different vibe than the effects I’ve been getting with DALL-E 3.
I’ve also noticed two issues - everything looks less cheerful and more beauty-AI-generated (like with Midjourney), plus the fact that each new image incurs a real cost has a serious impact on my willingness to experiment when each try costs real money, even if cheap 😃. However, I'll probably give it another chance, as the accuracy of the elements and lighting is truly top-notch, just lacks that bit of expressiveness DALL-E brings with itself.